Основы современных баз данных
Более точные оценки
Перейдем к рассмотрению подходов к более точным оценкам стоимости выполнения планов запроса. Эти подходы можно разбить на два класса. При использовании подходов первого класса оптимизатор сохраняет жесткую структуру, аналогичную структуре оптимизатора System R, но проведение оценок основывается на более точной статистической информации, характеризующей распределения значений. Предложения второго класса более революционны и исходят из того, что для произведения планов выполнения запросов и их оценок оптимизатор должен снабжаться некоторой информацией, характерной для конкретной области приложений.
При отказе от предположения о равномерности распределения значений поля отношения необходимо уметь установить реальное распределение значений. Существует два базовых подхода к оценкам распределения значений поля отношения: параметрический и основанный на методе сигнатур. Подход System R является тривиальным частным случаем метода параметрической оценки распределения - любое распределение оценивается как равномерное. В более развитом подходе было предложено использовать для оценки реального распределения значений поля отношения серию распределений Пирсона, в которую входят распределения от равномерного до нормального. Распределение выбирается из серии путем вычисления нескольких параметров на основе выборок реально встречающихся значений. Примеры практического применения этого подхода нам неизвестны.
Метод оценки распределения на основе сигнатур в целом можно описать следующим образом. Область значений поля разбивается на несколько интервалов. Для каждого интервала некоторым образом устанавливается число значений поля, попадающих в этот интервал. Внутри интервала значения считаются распределенными по некоторому фиксированному закону (как правило, принимается равномерное приближение). Рассмотрим два альтернативных подхода, связанных с сигнатурным описанием распределений.
При традиционном подходе область значений поля разбивается на N интервалов равного размера, и для каждого интервала подсчитывается число значений полей из кортежей данного отношения, попадающих в интервал.
Предположим, что EMP расширено еще одним полем AGE - возраст сотрудника. Пусть всего в организации работает 60 сотрудников в возрасте от 10 до 60 лет. Тогда гистограмма, изображающая распределение значений поля AGE может иметь вид, показанный ниже на рисунке. Гистограмма построена исходя из разбиения диапазона значений поля AGE на 10 интервалов.
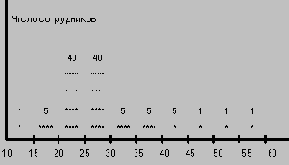
Рассмотрим, как можно оценивать селективность простых предикатов, задаваемых на поле AGE, с использованием такой гистограммы. Пусть в интервал значений AGE Si попадает Ki значений. Тогда SEL (EMP.AGE = const), если значение константы попадает в интервал значений Si, можно оценить следующим образом: 0 <= SEL (EMP.AGE) <= Ki/T (T - общее число кортежей в отношении EMP). Отсюда средняя оценка степени селективности предиката - Ki / (2 ( T). Например, SEL (AGE = 29) оценивается в 40/200 = 0.2, а SEL (AGE = 16) оценивается в 5/200 = 0.025. Это, конечно, существенно более точные оценки, чем те, которые можно получить, исходя из предположений о равномерности распределений. Но не так хорошо обстоят дела с оценками селективности простых предикатов с неравенствами.
Например, пусть требуется оценить степень селективности предиката EMP.AGE < const. Если значение константы попадает в интервал Si, и SUMi - суммарное количество значений AGE, попадающих в интервалы S1, S2, ..., Si, то SUMi-1 / T <= SEL (AGE < const) <= SUMi / T. Тогда средняя оценка степени селективности (SUMi-1 + SUMi) / (2 ( T), и ошибка оценки может достигать половины веса подобласти, в которую попадает значение константы предиката. Самое неприятное, что ошибка оценки зависит от значения константы и тем больше, чем больше значений поля содержится в соответствующем интервале гистограммы. Например, SEL (AGE < 29) оценивается как 46/100 <= SEL (AGE < 29) <= 86/100, откуда оценка степени селективности (46 + 86) / 200 = 0.66; при этом ошибка оценки может достигать 0.2. В то же время SEL (AGE < 49) оценивается существенно более точно.
Для устранения этого дефекта был предложен другой подход к описанию распределений значений поля отношения.
Идея подхода состоит в том, что множество значений поля разбивается на интервалы вообще говоря разного размера, чтобы в каждый интервал (кроме, вообще говоря, последнего) попадало одинаковое число значений поля. Количество интервалов выбирается исходя из ограничений по памяти, и чем оно больше, тем точнее получаемые оценки. При разбиении области значений на десять интервалов получаемая псевдогистограммная картина распределений значений поля AGE показана на рисунке ниже.
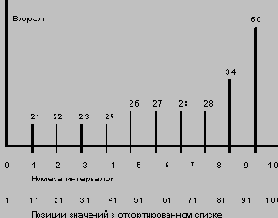
Область значений поля AGE отношения EMP разбита на 10 интервалов таким образом, что в каждый интервал попадает ровно по 10 значений поля AGE. Интервалы имеют разные размеры. Граничные значения интервалов показаны над вертикальными линиями. В псевдогистограмме допустимы интервалы, правая и левая граница которых совпадают, например, интервал (28,28). Он образовался по причине наличия в отношении EMP большого (большего десяти) числа кортежей со значением AGE = 28.
При использовании "псевдогистограммы" ошибки в оценках степеней селективности предикатов с операцией, отличной от равенства, уменьшаются. Размер ошибки не зависит от значения константы и уменьшается при увеличении числа интервалов.
Недостатком метода псевдогистограмм по сравнению с методом гистограмм является необходимость сортировки отношения по значениям поля для построения псевдогистограммы распределений значений этого поля. Известен подход, позволяющий получить достоверную псевдогистограмму без необходимости сортировки всего отношения.
Подход основывается на статистике Колмогорова, из которой применительно к случаю реляционных баз данных следует, что если из отношения выбирается образец из 1064 кортежей, и b - доля кортежей в образце со значениями поля C < V, то с достоверностью 99% доля кортежей во всем отношении со значениями поля C < V находится в интервале [b-0.05, b+0.05]. При уменьшении мощности образца достоверность, естественно, уменьшается.