Основы современных баз данных
Журнализация и восстановление в System R
Одно из основных требований к любой системе управления базами данных состоит в том, что СУБД должна надежно хранить базы данных. Это означает, что СУБД должна поддерживать средства восстановления состояния баз данных после любых возможных сбоев. К таким сбоям относятся индивидуальные сбои транзакций (например, деление на ноль в прикладной программе, инициировавшей выполнение транзакции); сбой процессора при работе СУБД (так называемые мягкие сбои) и сбои (поломки) внешних носителей, на которых расположены базы данных (жесткие сбои).
Ситуации, возникающие при сбоях каждого из отмеченных классов, различны и, вообще говоря, требуют разных подходов к организации восстановления баз данных. Индивидуальные сбои транзакций означают, что все изменения, произведенные в базе данных некоторой транзакцией, незаконны, и их необходимо устранить. Для этого необходимо выполнить индивидуальный откат транзакции такого же типа, как при выполнении RSS явной операции RESTORE.
При возникновении мягкого сбоя системы утрачивается содержимое оперативной памяти. Восстановление состояния базы данных состоит в том, что после его завершения база данных должна содержать все изменения, произведенные транзакциями, закончившимися к моменту сбоя, и не должна содержать ни одного изменения, произведенного транзакциями, которые к моменту сбоя не закончились. Существенным аспектом ситуации является то, что состояние базы данных на внешней памяти не разрушено, что позволяет сделать процесс восстановления не слишком длительным.
Жесткие сбои приводят к полной или частичной потере содержимого баз данных на внешней памяти. Тем не менее цель процесса восстановления та же, что и в случае мягкого сбоя: после завершения этого процесса база данных должна содержать все изменения, произведенные транзакциями, закончившимися к моменту сбоя, и не должна содержать ни одного изменения, произведенного транзакциями, не закончившимися к моменту сбоя. В случае жесткого сбоя единственно возможный подход к восстановлению состояния базы данных может быть основан на использовании ранее произведенной копии базы данных.
В общем случае процесс восстановления после жесткого сбоя существенно более накладен, чем после мягкого сбоя.
Алгоритмы восстановления System R основаны на двух базовых средствах - ведении журнала и поддержке теневых состояний сегментов. Рассмотрим сначала механизм журнализации. Мы уже упоминали о наличии журнала в предыдущих подразделах. Журнал - это отдельный файл внешней памяти, для которого для надежности обычно поддерживаются две копии, и в который помещается информация обо всех операциях изменения состояния базы данных. В предыдущем подразделе мы упоминали об использовании журнала для отката транзакции по явной операции RESTORE или при неявных откатах при разрушении тупиков. Та же схема употребляется и при откатах индивидуальных транзакций при сбоях.
Механизм индивидуального отката основан на обратном выполнении всех изменений, произведенных данной транзакцией (undo). При этом из журнала в обратном хронологическому порядке выбираются все записи об изменении базы данных, произведенные от имени данной транзакции. Для этого необходима идентификация всех записей в журнале. В System R все записи одной транзакции связываются в один список в порядке, обратном хронологическому. Ссылка в списке представляет собой адрес записи в файле-журнале. Поскольку схема индивидуального отката едина для всех ситуаций индивидуальных сбоев, в частности для ситуации разрушения тупиков, то обратное выполнение операций сопровождается снятием установленных при прямой работе транзакции синхронизационных захватов с объектов базы данных. Следовательно, после выполнения индивидуального отката транзакции ситуация в системе такова, как если бы транзакция никогда и не начиналась.
Специфика мягкого сбоя системы состоит в утрате состояния оперативной памяти. В оперативной памяти находятся буфера базы данных. Поддерживаются буфера двух сортов: буфера журнала и буфера собственно базы данных. Буфера журнала содержат последние записи в журнал. Имеются два буфера журнала. Как только один буфер полностью заполняется, производится его запись в файл-журнал и продолжается заполнение второго буфера.
Таким образом, при обычной работе системы обмены с файлом журнала не приводят к приостановке работы. Буфера базы данных содержат копии страниц базы данных, которые использовались в последнее время. В силу обычных в программировании принципов локализации ссылок достаточно вероятно, что после помещения копии страницы базы данных в буфер эта страница потребуется в ближайшем будущем. Поэтому наличие копии страницы в буфере позволит избежать обмена с устройством внешней памяти, когда эта страница понадобится в следующий раз.
Заметим, что размер буферного пула СУБД во многом определяет ее производительность. Обычная реляционная СУБД, такая, как System R, при наличии достаточного размера буферного пула вполне конкурентоспособна по отношению к системам, основанным на специализированной аппаратуре машин баз данных.
Задача System R по обеспечению надежного завершения транзакций, т.е. гарантированному наличию произведенных ими изменений в базе данных, требует наличия во внешней памяти информации об этих изменениях. Для этого при окончании любой транзакции поддерживается гарантированное присутствие в файле-журнале всех записей об изменениях, произведенных этой транзакцией. При использовании буферизации для записи в журнал для этого достаточно насильственно вытолкнуть во внешнюю память недозаполненный буфер журнала. Под насильственным выталкиванием понимается запись буфера во внешнюю память в соответствии не с логикой ведения журнала, а с логикой окончания транзакции. Только после произведения такого насильственного выталкивания буфера журнала транзакция считается закончившейся. Заметим, что последней записью в журнале от любой изменяющей базу данных транзакции является запись о конце транзакции. Эти записи используются при восстановлении. Рассмотрим теперь (пока не совсем точно) как осуществляется в System R восстановление базы данных после мягкого сбоя.
Основой алгоритма восстановления является то, что система придерживается правила упреждающей записи в журнал (WAL - Write Ahead Log).
Это правило означает, что при выталкивании любой страницы из буфера страниц сначала гарантируется наличие в файле журнала записи, относящейся к изменениям этой страницы после момента ее выталкивания в буфер. Поскольку записи в журнал блокируются, то для соблюдения правила WAL перед выталкиванием страницы данных необходимо вытолкнуть недозаполненный буфер журнала, если он содержит запись, относящуюся к изменению страницы. Применение правила WAL гарантирует, что если во внешней памяти находится страница базы данных, то в файле журнала находятся все записи об операциях, вызвавших изменение этой страницы. Обратное неверно: в файле журнала могут содержаться записи об изменении некоторых страниц базы данных, а сами эти изменения могут быть не отражены в состояниях страниц во внешней памяти.
При окончании любой транзакции (т.е. выполнении операции RSS END TRANSACTION) производится выталкивание недозаполненного буфера журнала и тем самым гарантируется наличие в журнале полной информации обо всех изменениях, произведенных данной транзакцией. Насильственное выталкивание страниц буфера базы данных не производится (слишком накладно было бы производить такие выталкивания при окончании любой транзакции). Тем самым после мягкого сбоя состояние базы данных во внешней памяти может не соответствовать тому, которое должно было бы быть после окончания транзакций. Следовательно, после мягкого сбоя некоторые страницы во внешней памяти могут не содержать информации, помещенной в них уже закончившимися транзакциями, а другие страницы могут содержать информацию, помещенную транзакциями, которые к моменту сбоя не закончились. При восстановлении необходимо добавить информацию в страницах первого типа и удалить информацию в страницах второго типа.
System R периодически устанавливает системные контрольные точки. Более подробно мы остановимся на этом ниже. Пока заметим лишь, что при установлении такой контрольной точки производится насильственное выталкивание во внешнюю память буфера журнала и всех буферов страниц.
Это дорогостоящая операция, и выполняется она достаточно редко. При каждой системной контрольной точке в журнал помещается специальная запись.
Предположим, что последняя системная контрольная точка устанавливалась в момент времени tc, а мягкий сбой произошел в некоторый более поздний момент времени tf. Тогда все транзакции системы можно разбить на пять категорий.
Транзакции категории Т1 начались и кончились до момента tc. Следовательно, все произведенные ими изменения базы данных надежно находятся во внешней памяти, и по отношению к ним никаких действий при восстановлении производить не нужно. Транзакции категории Т2 начались до момента tc, но успели кончиться к моменту мягкого сбоя tf. Изменения, произведенные такими транзакциями после момента tc, могли не попасть во внешнюю память, и при восстановлении должны быть повторно произведены. Транзакции категории Т3 начались до момента tc, но не кончились к моменту сбоя. Все их изменения, произведенные до момента tc, и, возможно, некоторые изменения, произведенные после момента tc, содержатся во внешней памяти. При восстановлении их необходимо удалить. Транзакции категории Т4 начались после момента установки системной контрольной точки и успели закончиться до момента сбоя. Их изменения могли не отобразиться во внешнюю память; при восстановлении их необходимо выполнить повторно. Наконец, транзакции категории Т5 начались после момента tc и не закончились к моменту сбоя. Их изменения должны быть удалены из страниц во внешней памяти.
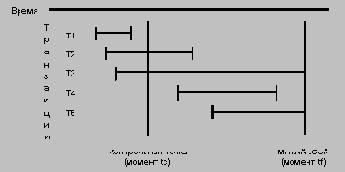
В принципе можно было бы выполнить все необходимые восстановительные действия после мягкого сбоя, основываясь только на информации из журнала. Однако в System R ситуация несколько упрощается за счет применения техники теневых страниц. Принцип теневых страниц давно использовался в файловых системах, поддерживающих файлы со страничной организацией. В соответствии с этим принципом после открытия файла на изменение модифицированные страницы записываются на новое место внешней памяти (т.е. под них выделяются свободные блоки внешней памяти).
При этом во внешней памяти сохраняется старая (теневая) таблица отображения страниц файла во внешнюю память, а в оперативной памяти по ходу изменения файла формируется новая таблица. При закрытии файла заново сформированная таблица записывается во внешнюю память, образуя новую теневую таблицу, а блоки внешней памяти, содержащие предыдущие образы страниц файла, освобождаются. При сбое процессора тем самым автоматически сохраняется состояние файла, в котором он находился перед последним открытием (конечно, с возможной потерей некоторых блоков внешней памяти, которые затем собираются с помощью специальной утилиты). Допускаются операции явной фиксации текущего состояния файла и явного отката состояния файла к точке последней фиксации.
В System R применяется развитие идей теневого механизма в контексте мультидоступных баз данных. Как мы уже отмечали, сегменты баз данных System R представляют собой файлы со страничной организацией. Соответственно, существуют и таблицы приписки этих файлов в блоки внешней памяти. При выполнении операции установки системной контрольной точки после выталкивания буферов страниц во внешнюю память таблицы отображения всех сегментов также фиксируются во внешней памяти, т.е. становятся теневыми. Далее до следующей контрольной точки доступ к страницам сегментов производится через таблицы отображения, располагаемые в оперативной памяти, и каждая изменяемая страница любого сегмента записывается на новое место внешней памяти с коррекцией соответствующей текущей таблицы отображения.
Тогда, если происходит мягкий сбой, все сегменты автоматически переходят в состояние, соответствующее последней системной контрольной точке, т.е. изменения, произведенные позже момента установления этой контрольной точки, в них просто не содержатся.
Это достаточно сильно упрощает процедуру восстановления после мягкого сбоя. Система вообще не должна предпринимать никаких действий по отношению к изменениям транзакций типа Т5: этих изменений нет во внешней памяти. При восстановлении достаточно выполнить обратные изменения транзакций типа Т3 (undo в терминологии System R), повторно выполнить изменения транзакций типа Т2 (redo в терминологии System R; заметим, кстати, что эти изменения можно теперь выполнять безусловно, не заботясь о том, что они, возможно, и так содержатся во внешней памяти).
Кроме того, нужно просто повторить изменения транзакций типа Т4. Естественно, что начинать действия по журналу следует с записи о последней контрольной точке.
Справедливости ради отметим, что на самом деле теневой механизм используется в System R главным образом не для упрощения процедуры восстановления после мягкого сбоя. Как мы уже отмечали, без этого можно обойтись. Главная причина в другом, а именно, в том, что восстановление базы данных можно начинать только от ее физически согласованного состояния. Дело в том, что в журнал помещается информация об изменении объектов базы данных, а не страниц. Например, в журнале может находиться информация о модификации кортежа в виде триплета <tid, старое состояние кортежа, новое состояние кортежа>. Реально же при выполнении операции модификации изменяются несколько страниц: исходная страница; возможно, страница замены, если кортеж не поместился в исходную страницу; страницы индексов. И так происходит при выполнении любой операции изменения базы данных. Поскольку буфера страниц выталкиваются во внешнюю память по отдельности, то к моменту мягкого сбоя во внешней памяти может возникнуть набор физически рассогласованных страниц, не соответствующий никакой журнализуемой операции. При таком состоянии внешней памяти восстановление по журналу невозможно.
Когда выполняется операция установки системной контрольной точки, то до насильственного выталкивания буферов страниц система дожидается завершения всех операций всех транзакции и до окончания выталкивания не допускает выполнения новых операций. Поэтому теневое состояние всех сегментов базы данных физически согласовано и может служить основой восстановления по журналу.
При жестких сбоях утрачивается содержимое всех или части сегментов базы данных. Для восстановления базы данных используются журнал и ранее произведенная копия базы данных. В System R допускается посегментное восстановление. Для этого копия сегмента переписывается с архивного носителя на заново выделенный рабочий носитель, а затем по журналу повторяются все изменения, производившиеся в объектах этого сегмента после момента копирования.
Поскольку в момент жесткого сбоя содержимое оперативной памяти не утрачивается, то возможно продолжение выполнения транзакций после завершения восстановления. Более того, если авария коснулась только части сегментов базы данных, то транзакции на фоне процесса восстановления могут продолжать работу с объектами базы данных, расположенными в неповрежденных сегментах.
Единственным требованием к архивной копии сегмента является то, что она должна находиться в согласованном состоянии (поскольку восстановление ведется в терминах записей журнала). Поэтому для создания архивной копии сегмента достаточно лишь дождаться конца выполнения операций над объектами данного сегмента и запретить начало новых операций до конца копирования. Тем самым, выполнение архивной копии не требует перевода системы в какой-либо особый режим работы и только незначительно тормозит нормальную работу транзакций.
В заключение данного подраздела заметим, что в первых версиях System R в качестве архивного носителя использовались магнитные ленты. Однако со временем стало ясно, что во-первых, надежность магнитных лент существенно меньше надежности магнитных дисков, а во-вторых, они стали уступать и в емкости. Поэтому в последних версиях системы использовалась только дисковая память.
И последнее замечание. Журнал System R располагается в файле большого, но постоянного размера. Он используется в циклическом режиме. Когда записи журнала достигают конца файла, они начинают помещаться в его начало. Поскольку переход на начало файла можно считать утратой предыдущего журнала, этот переход сопровождается копированием сегментов базы данных. В некоторых других системах используется архивизация самого журнала.